摘 要 随着大型语言模型(LLM)以及检索增强生成(RAG)技术的快速发展,通过该技术实现垂直领域知识的快速检索查询,已经是目前各行业智能化发展的趋势。文章以轨道交通标准规范检索查询场景为例,详细介绍了如何构建一个基于LLM和RAG技术的轨道交通标准规范知识库系统。结果表明了该系统在标准规范知识快速查询检索应用场景中的有效性,并可进一步向其他业务场景扩展。
关键词 大语言模型;LLM;检索增强生成;RAG;LlamaIndex
在人工智能科技创新的浪潮中,以LLM为代表的AI技术已然跃升为重塑产业生态的核心驱动力。依托大模型超大规模的参数体系,以及极为卓越的自学习、自适应能力,正在为各行业创新发展带来新动力。但是,由于LLM在垂直领域知识的局限性,难以有效回答私有领域的问题,在垂直领域的应用发展还有很多局限性。随着RAG技术发展,能够很好的解决上述问题,特别在轨道交通运营管理业务场景中能发挥出巨大作用。
1 知识库使用现状
轨道交通运营企业在日常生产管理活动中,不断积累沉淀形成了海量的私有知识库,例如标准规范、设备维修履历、事件事故案例等,本案例以标准规范知识库作为业务场景。通过对国内城市轨道交通运营企业标准规范编制情况的调研,根据运营企业的企业规模、运营线路、组织机构、开展业务的不同,所建立的标准规范数量为500至2000册不等。对于这些海量的标准规范文档,很多运营企业已经通过信息化技术进行管理,例如构建了知识库系统、档案管理系统、办公自动化系统等。这些系统具备了标准规范知识文档存储和在线阅读功能,但是在知识的查询检索方面,主要还是基于关键字匹配技术,无法通过自然语言快速获取所需知识。在一些应急处置、故障处理等特殊场景下,知识的快速获取可以帮助一线员工提高处置效率。
2 相关技术介绍
2.1 LLM及RAG
LLM 是基于深度学习技术的大规模自然语言处理模型,但是LLM 仅能基于训练数据获取知识,而无法处理超出训练数据范围的特定领域问题。为了弥补这一不足,RAG技术可以通过外部知识检索的方式增强 LLM 的生成能力,有效减少LLM幻觉现象,提高模型在垂直领域中的回答精度。
2.2 LlamaIndex
是一个专为构建基于LLM的RAG应用的开源框架,核心功能包括数据连接、索引构建、增强检索及与LLM的无缝集成,支持开发者在私有或特定领域数据上构建智能问答、知识代理等应用。
3 系统构建与实现
3.1 总体框架设计
本案例除了运用了LLM,还使用了Embeddings、Reranking等模型(见图1),Embeddings模型主要用于文本向量化和相似度检索;Rerank模型主要用于将检索生成的文本进行重排序,提高查询质量;LLM用于将答案组织为自然语言返回用户,工作过程如图1所示。
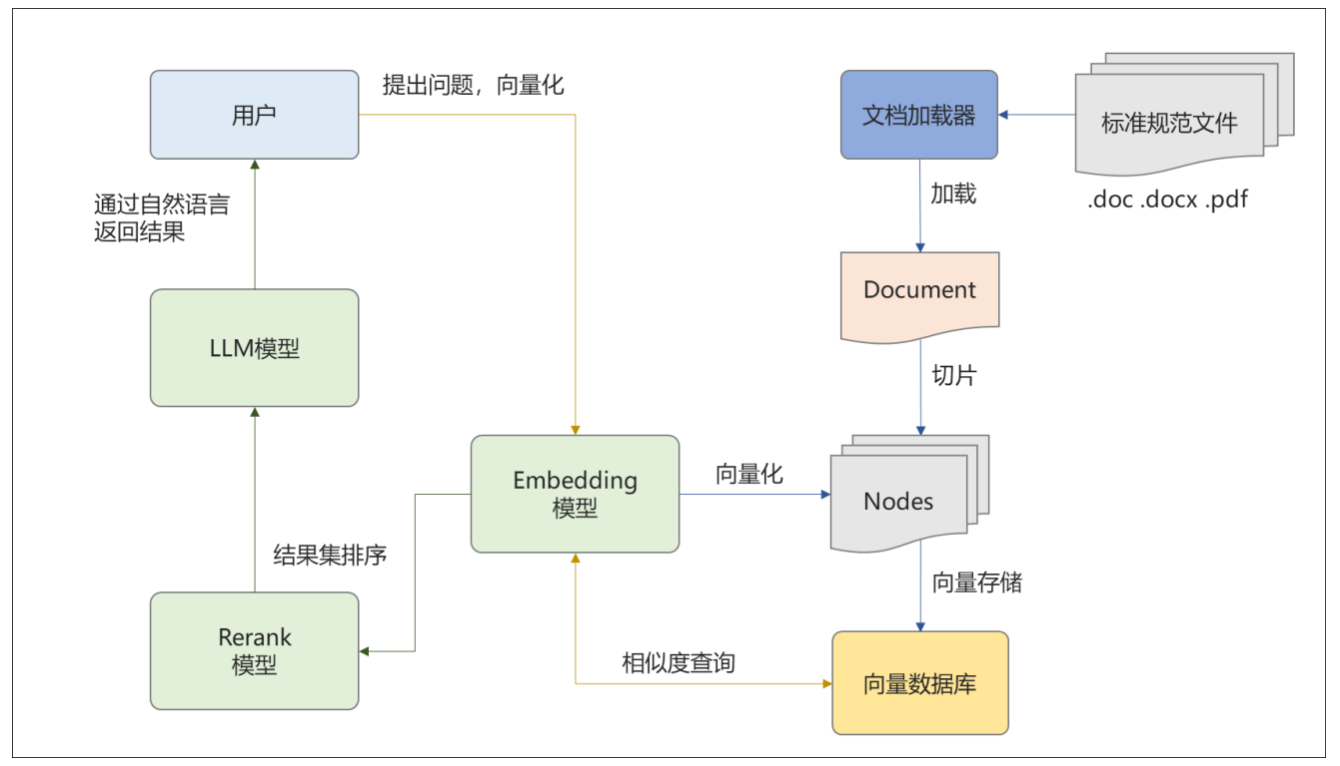
图1 工作过程
Fig.1 Working Process
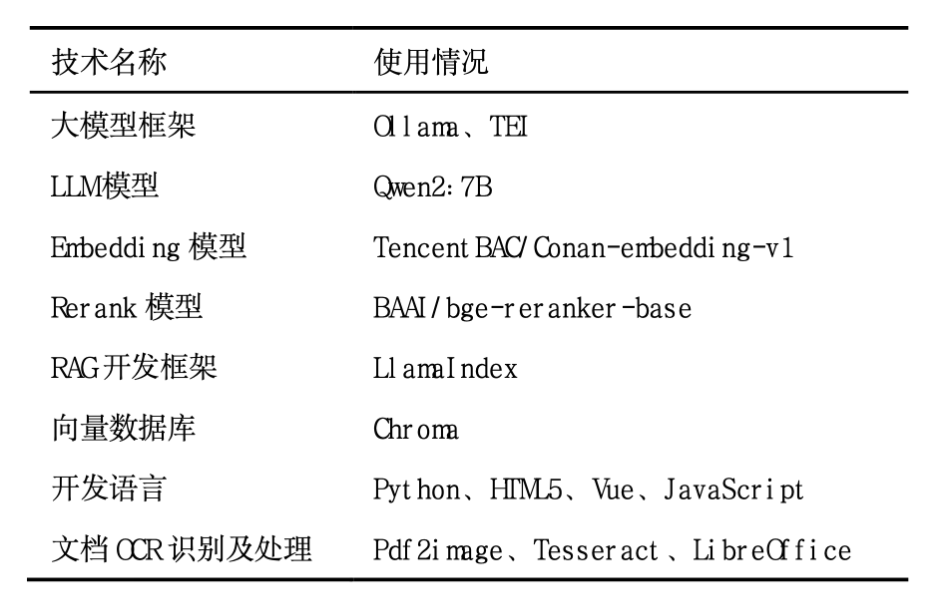
在技术实现方面,目前主流的大模型服务框架主要有Ollama、TEI、vLLM等,RAG开发框架主要有LlamaIndex、LangChain、Dify等,向量数据库主要有Chroma、Milvus、Weaviate等。本案例通过对上述框架的能力、技术成熟度、硬件投入等方面进行比较评估,最终选择了Ollama、TEI、LlamaIndex、Chroma的技术路线,Ollama用于运行LLM,TEI用于本地部署Embedding和Rerank模型具体采用的组件、模型见表1。
表1 技术配置表
Tab.1 Technical Configuration Table
本案例的主要功能模块如图2所示,Main为入口主程序,Model Index Init为模型、向量索引初始化模块,Data Compare是数据对比模块,Gen/Rm Vector是向量新增或删除模块,Database Util、File Util分别是知识源数据库读取和文档处理工具模块,API router是前端API接口的路由模块,Auth是用户身份验证模块。
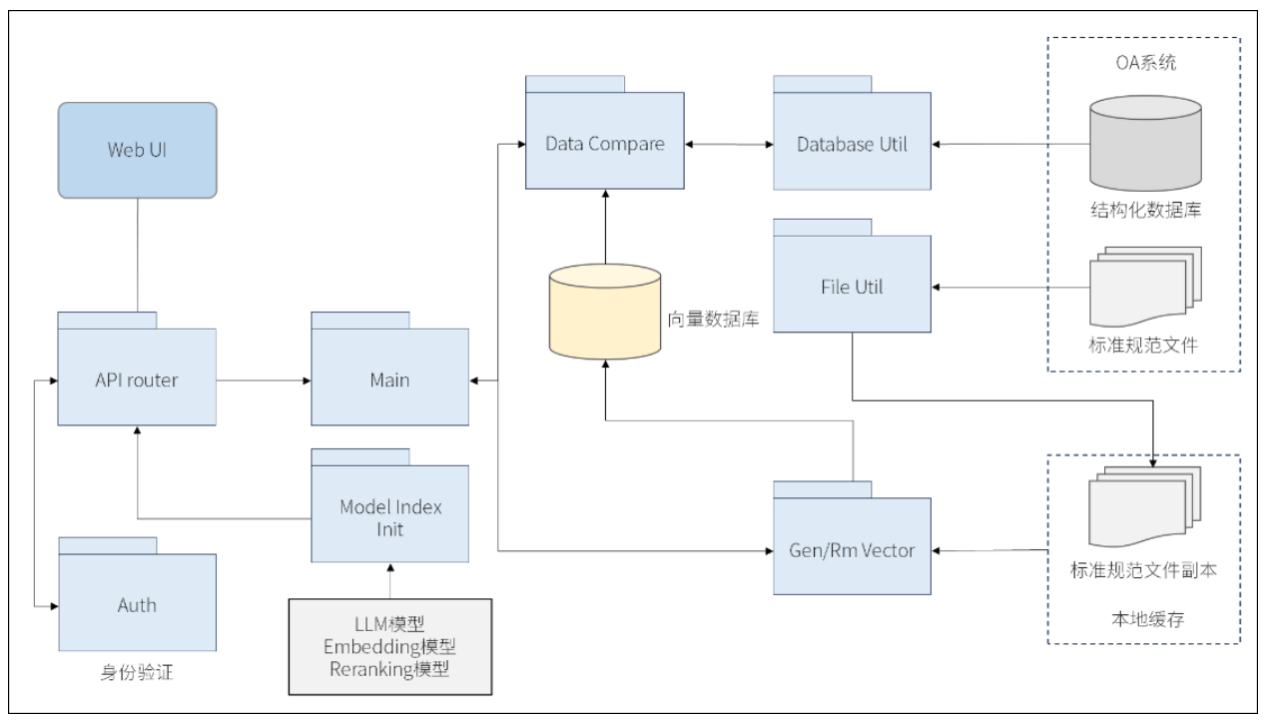
图2 主要功能模块
Fig.2 Main functional modules
3.2 知识自动读取及更新
RAG应用的知识读取质量决定了问题解答的准确性,因此,RAG应用需要与现有的知识管理系统集成,并实现知识自动摄取及更新才能保证数据质量。本案例的RAG应用主要与办公自动化(OA)系统集成,主程序启动后通过定时任务调度Data Compare模块,和OA知识库当前实时数据进行比对,比对方法主要通过向量数据库中元数据的ID和文本哈希值进行一致性比对,发现不一致数据时启动Gen/Rm Vector模块进行向量更新和删除操作。为保证数据检索的准确性和一致性,在向量数据库、向量索引更新时需要对相关资源加锁,待更新接收后解锁。
3.3 文档读取及分块
LlamaIndex中有丰富的数据连接器,可以直接读取各种文本文档,比如txt、docx和pdf格式的文档。本案例中OA知识库中的标准规范文档主要为docs格式,少部分doc和pdf格式。由于数据连接器不能直接读取doc格式文档,本案例通过调用LibreOffice将doc格式转换为docx格式以后再进行数据读取。另外,部分pdf文档为扫描格式,数据连接器也无法直接读取,本案例通过OCR工具进行处理后再进行数据读取。文档在读取的同时还需要进行哈希计算,哈希值保存在文本读取后的元数据中,以便进行版本更新时的数据比对。
文本读取后,再通过LlamaIndex的文本切割器对文本进行切割分块。在分块过程中,需要注意分块大小(chunk_size)和文本重叠(chunk_overlap)两个参数,设置较大,可以提供更连贯的上下文,但会增加计算量;设置较小,虽然可以减少计算量,但可能会导致上下文断裂,直接影响查询结果的准确性,因此需要综合考虑计算能力、成本和准确性接受度,本案例chunk_size设置为512,chunk_overlap设置为50。数据分块以后,通过LlamaIndex的向量处理模块将生成的文本块向量化以后存入向量数据库,并生成向量索引,本案例的向量生成算法采用余弦相似度算法。
3.4 知识检索及应答
知识检索及应答功能部分,用户通过前端交互界面提出相关问题,后端接收到以后,通过Model Index Init构建检索器、响应生成器和查询引擎等对象,将用户问题向量化以后,通过向量数据库进行相似度查询后,将检索查询到的结果通过Reranking模型进行排序质量优化后返回用户端。在检索器初始化时,需要合理设置top_k参数,这个参数的意义在于大模型生成答案或者做预测的时候,会有很多可能的结果,top_k参数就是让模型只考虑其中概率最高的k个结果,因此,top_k参数同样影响系统性能和结果的准确性,需要根据计算能力不断进行测试和调优。
4 系统测试和分析
本案例系统计算环境采用了云服务商提供的GPU服务器,配置为8核虚拟CPU,64G内存,GPU单元为NVIDIA Tesla P4的入门级显卡,显存为32G,系统平均响应速度约为6秒,检索效果见图3。
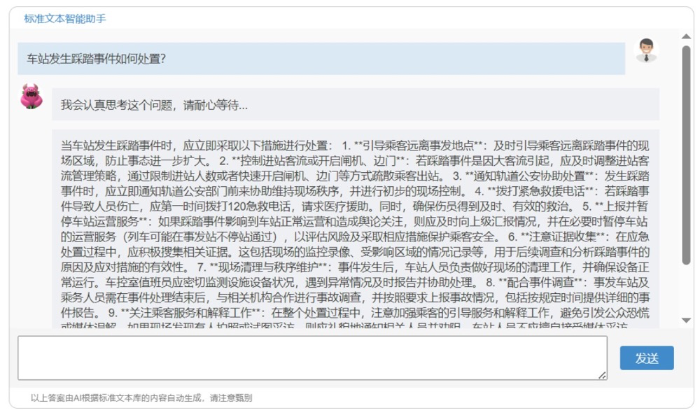
图3 知识检索效果图
Fig.2 Knowledge retrieval rendering
系统自动采集了OA系统中1821份标准规范文档,经过测试,相关问题回答的准确性约为92%,测试结果见表2。
表2 准确性测试评分表
Tab.2 Accuracy Test Score Sheet

经过测试,本系统已经能满足标准规范知识库的“索引-检索-生成”等基本需求,但受限于资金成本、算力环境、研发技术等条件限制,在准确性和性能方面还存在一些问题。在准确性方面,由于标准规范文档中存在图、表的内容,当前未使用多模态技术进行图、表解析,查询内容涉及图、表内容时,准确性相对较差;另外,系统目前仅采用了向量索引方式,索引方式也较为单一。在性能方面,当前计算环境采用的是入门级配置,对于高并发场景还存在性能瓶颈。
后续,在算力满足的前提下,系统还可进一步优化检索前后策略,增加关键字、摘要等检索方式,完善多模态数据识别、采集功能提高系统检索的准确性,同时,可以进一步通过工作流、Agent、MCP等技术进一步扩宽应用场景,特别在应急处置、故障处理、运营管理数据分析等方面能发挥积极作用。
5 结语
本文提出了基于LLM和RAG的轨道交通标准规范知识库系统的研究,系统利用LLM、Embedding、Rerank等模型结合向量数据库,解决了LLM在垂直领域知识检索准确性不高的问题。测试结果验证了该系统在城市轨道交通标准规范知识快速查询检索应用场景中的有效性,展现了将大模型应用于垂直领域的潜力。未来,系统将不断优化完善,从目前的朴素RAG向高级RAG、多模态RAG以及Agent等技术方向进化,不断探索更多应用场景,并推进城市轨道交通智能化创新。